MQTT Sink¶
Download connector MQTT Connector 1.2 for Kafka MQTT Connector 1.1 for Kafka
This MQTT sink connector allows you to write message from Kafka to MQTT brokers.
Prerequisites¶
- Apache Kafka 0.11.x of above
- Kafka Connect 0.11.x or above
- Mqtt server
- Java 1.8
Features¶
- The KCQL routing querying - Topic to measure mapping and Field selection
- Error policies for handling failures
- Payload support for Schema.Struct and payload Struct, Schema.String and JSON payload and JSON payload with no schema.
KCQL Support¶
INSERT INTO mqtt_topic SELECT { FIELD, ... } FROM kafka_topic_name
Tip
You can specify multiple KCQL statements separated by ; to have a the connector sink multiple topics.
The MQTT sink supports KCQL, Kafka Connect Query Language. The following support KCQL is available:
- Field selection
- Target MQTT topic selection.
Examples:
-- Insert into /landoop/demo all fields from kafka_topicA
INSERT INTO /landoop/demo SELECT * FROM kafka_topicA
Payload Support¶
Schema.Struct and a Struct Payload¶
If you follow the best practice while producing the events, each message should carry its schema information. The best option is to send AVRO. Your Connector configurations options include:
key.converter=io.confluent.connect.avro.AvroConverter
key.converter.schema.registry.url=http://localhost:8081
value.converter=io.confluent.connect.avro.AvroConverter
value.converter.schema.registry.url=http://localhost:8081
This requires the SchemaRegistry.
Note
This needs to be done in the connect worker properties if using Kafka versions prior to 0.11
Schema.String and a JSON Payload¶
Sometimes the producer would find it easier to just send a message with
Schema.String and a JSON string. In this case your connector configuration should be set to value.converter=org.apache.kafka.connect.json.JsonConverter.
This doesn’t require the SchemaRegistry.
key.converter=org.apache.kafka.connect.json.JsonConverter
value.converter=org.apache.kafka.connect.json.JsonConverter
Note
This needs to be done in the connect worker properties if using Kafka versions prior to 0.11
No schema and a JSON Payload¶
There are many existing systems which are publishing Json over Kafka and bringing them in line with best practices is quite a challenge, hence we added the support. To enable this support you must change the converters in the connector configuration.
key.converter=org.apache.kafka.connect.json.JsonConverter
key.converter.schemas.enable=false
value.converter=org.apache.kafka.connect.json.JsonConverter
value.converter.schemas.enable=false
Note
This needs to be done in the connect worker properties if using Kafka versions prior to 0.11
Error Polices¶
Landoop sink connectors support error polices. These error polices allow you to control the behaviour of the sink if it encounters an error when writing records to the target system. Since Kafka retains the records, subject to the configured retention policy of the topic, the sink can ignore the error, fail the connector or attempt redelivery.
Throw
Any error on write to the target system will be propagated up and processing is stopped. This is the default behavior.
Noop
Any error on write to the target database is ignored and processing continues.
Warning
This can lead to missed errors if you don’t have adequate monitoring. Data is not lost as it’s still in Kafka subject to Kafka’s retention policy. The sink currently does not distinguish between integrity constraint violations and or other exceptions thrown by any drivers or target systems.
Retry
Any error on write to the target system causes the RetryIterable exception to be thrown. This causes the Kafka Connect framework to pause and replay the message. Offsets are not committed. For example, if the table is offline it will cause a write failure, the message can be replayed. With the Retry policy, the issue can be fixed without stopping the sink.
Lenses QuickStart¶
The easiest way to try out this is using Lenses Box the pre-configured docker, that comes with this connector pre-installed. You would need to Connectors –> New Connector –> Sink –> MQTT and paste your configuration
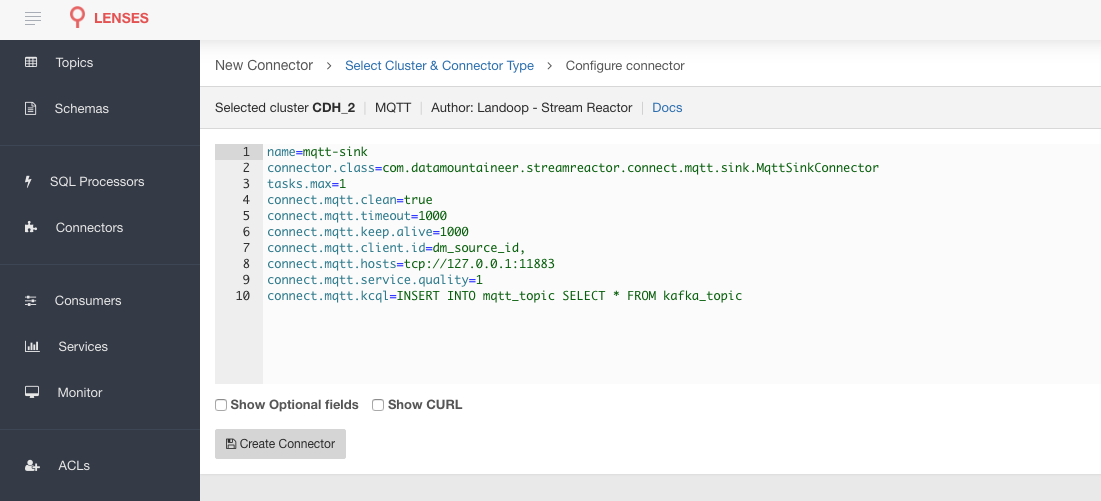
MQTT Setup¶
HiveMQ, who provides enterprise MQTT brokers have a web client. We’ll use it for the quickstart. Go to this link, connect and set
up a subscription to /landoop/mqtt_sink_topic/+ topic. You should see this.
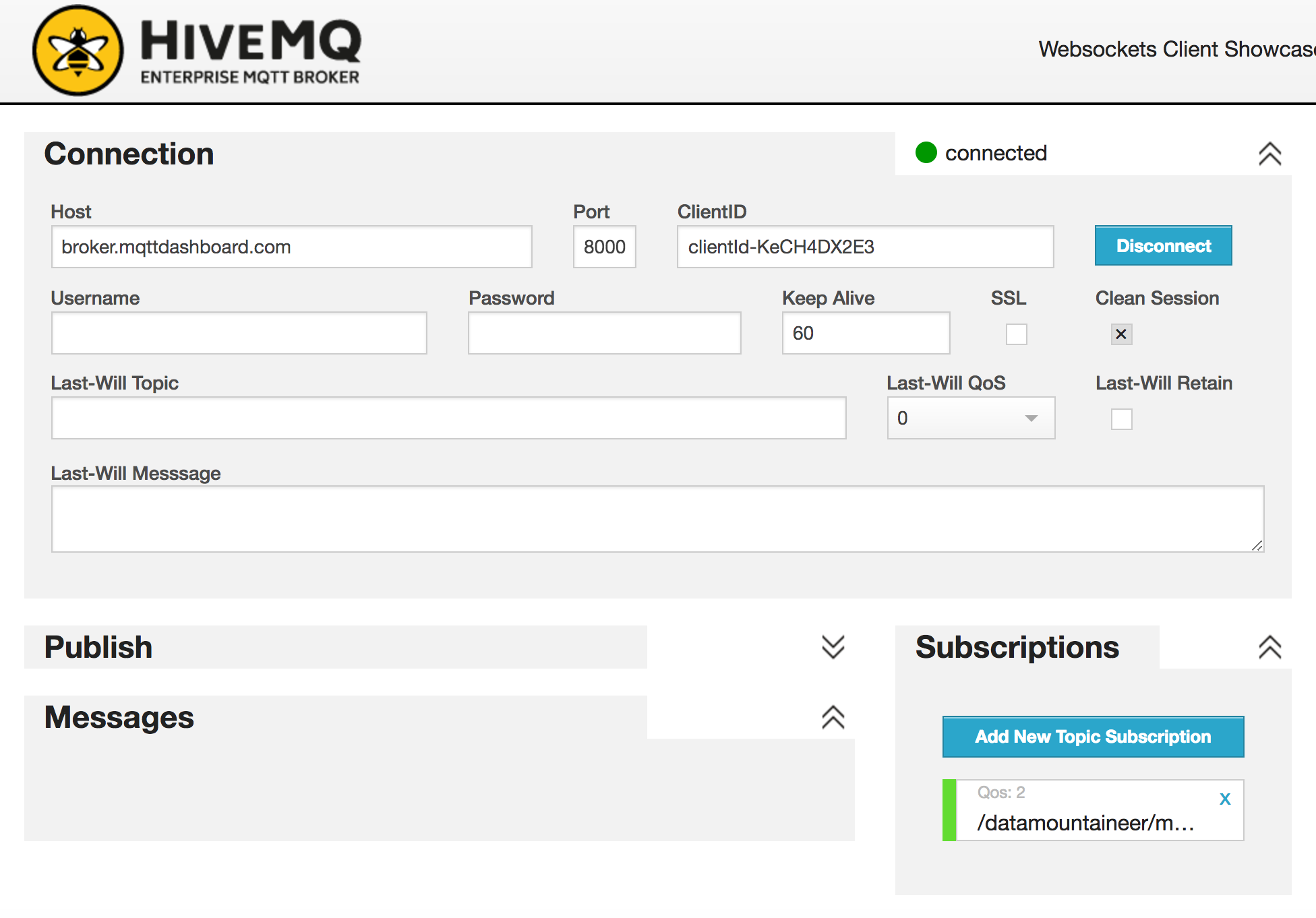
Now we have a web client listening for messages which will come from the MQTT Sink.
Installing the Connector¶
Connect, in production should be run in distributed mode
- Install and configure a Kafka Connect cluster
- Create a folder on each server called
plugins/lib - Copy into the above folder the required connector jars from the stream reactor download
- Edit
connect-avro-distributed.propertiesin theetc/schema-registryfolder and uncomment theplugin.pathoption. Set it to the root directory i.e. plugins you deployed the stream reactor connector jars in step 2. - Start Connect,
bin/connect-distributed etc/schema-registry/connect-avro-distributed.properties
Connect Workers are long running processes so set an init.d or systemctl service accordingly.
Sink Connector QuickStart¶
Start Kafka Connect in distributed mode (see install).
In this mode a Rest Endpoint on port 8083 is exposed to accept connector configurations.
We developed Command Line Interface to make interacting with the Connect Rest API easier. The CLI can be found in the Stream Reactor download under
the bin folder. Alternatively the Jar can be pulled from our GitHub
releases page.
Starting the Connector¶
Download, and install Stream Reactor. Follow the instructions here if you haven’t already done so. All paths in the quickstart are based on the location you installed the Stream Reactor.
Once the Connect has started we can now use the kafka-connect-tools cli to post in our distributed properties file for MQTT. For the CLI to work including when using the dockers you will have to set the following environment variable to point the Kafka Connect Rest API.
export KAFKA_CONNECT_REST="http://myserver:myport"
➜ bin/connect-cli create mqtt-sink < conf/mqtt-sink.properties
name=mqtt-sink
connector.class=com.datamountaineer.streamreactor.connect.mqtt.sink.MqttSinkConnector
tasks.max=1
topics=kafka-topic
connect.mqtt.hosts=tcp://broker.mqttdashboard.com:1883
connect.mqtt.clean=true
connect.mqtt.timeout=1000
connect.mqtt.keep.alive=1000
connect.mqtt.service.quality=1
connect.mqtt.client.id=dm_sink_id,
connect.mqtt.kcql=INSERT INTO /landoop/mqtt_topic SELECT * FROM kafka-topic
If you switch back to the terminal you started Kafka Connect in, you should see the Elastic Search Sink being accepted and the task starting.
INFO
__ __
/ / ____ _____ ____/ /___ ____ ____
/ / / __ `/ __ \/ __ / __ \/ __ \/ __ \
/ /___/ /_/ / / / / /_/ / /_/ / /_/ / /_/ /
/_____/\__,_/_/ /_/\__,_/\____/\____/ .___/
/_/
__ _______ ____________ _____ _ __
/ |/ / __ \/_ __/_ __/ / ___/(_)___ / /__
/ /|_/ / / / / / / / / \__ \/ / __ \/ //_/ By Andrew Stevenson
/ / / / /_/ / / / / / ___/ / / / / / ,<
/_/ /_/\___\_\/_/ /_/ /____/_/_/ /_/_/|_|
(com.datamountaineer.streamreactor.connect.mqtt.sink.MqttSinkTask:41)
We can use the CLI to check if the connector is up but you should be able to see this in logs as well.
#check for running connectors with the CLI
➜ bin/connect-cli ps
mqtt-sink
Test Records¶
Tip
If your input topic doesn’t match the target use Lenses SQL to transform in real-time the input, no Java or Scala required!
Now we need to put some records it to the kafka-topic topics. We can use the kafka-avro-console-producer to do this.
Start the producer and pass in a schema to register in the Schema Registry. The schema has a firstname field of type
string, a lastname field of type string, an age field of type int and a salary field of type double.
bin/kafka-avro-console-producer \
--broker-list localhost:9092 --topic kafka-topic \
--property value.schema='{"type":"record","name":"User","namespace":"com.datamountaineer.streamreactor.connect.mqtt"
,"fields":[{"name":"firstName","type":"string"},{"name":"lastName","type":"string"},{"name":"age","type":"int"},{"name":"salary","type":"double"}]}'
Now the producer is waiting for input. Paste in the following:
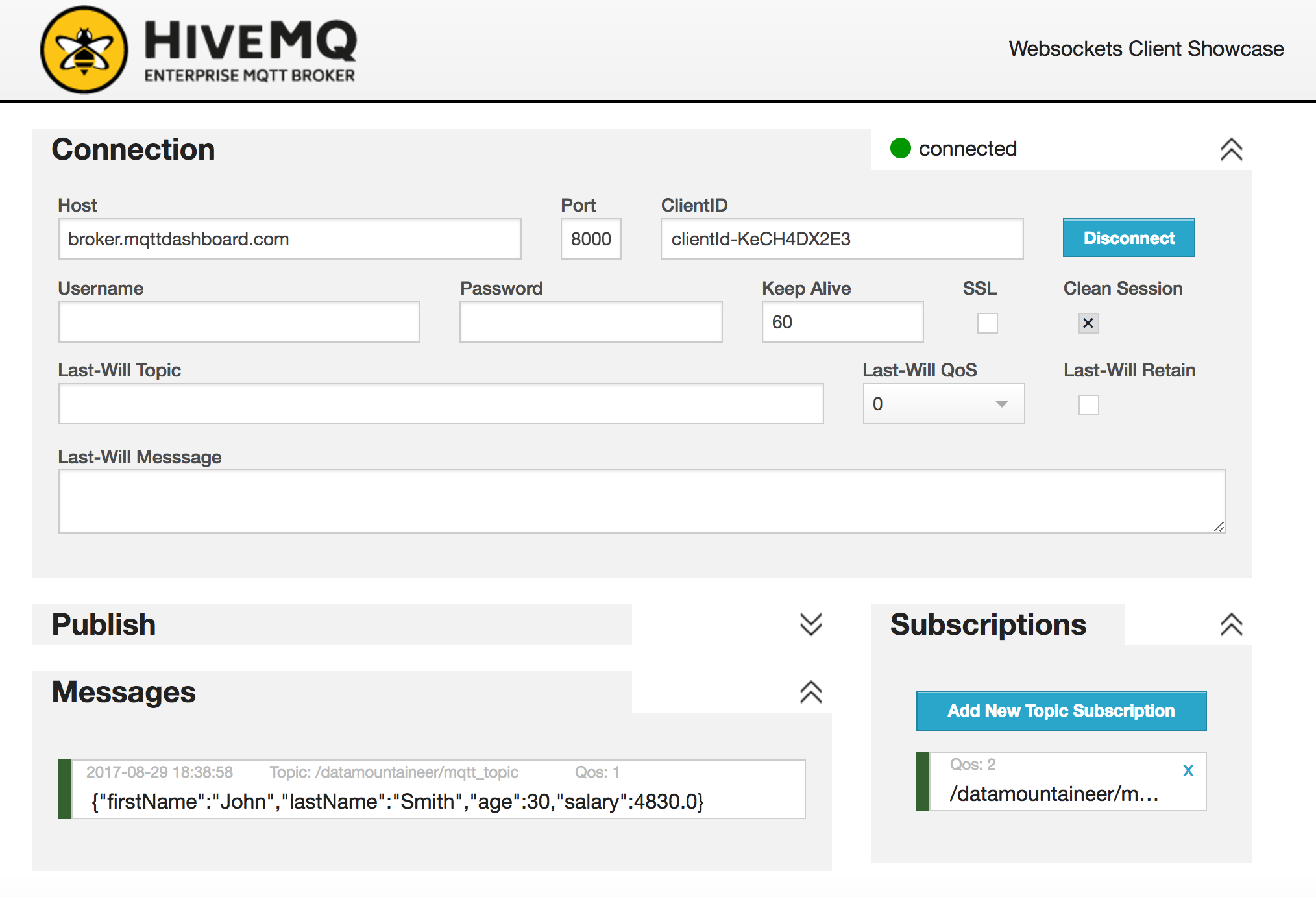
{"firstName": "John", "lastName": "Smith", "age":30, "salary": 4830}
Check for Records in the MQTT Broker¶
Go back to the browser you started the HiveMQ web client in. You should see the messages arrive in the messages section.
Configurations¶
The Kafka Connect framework requires the following in addition to any connectors specific configurations:
| Config | Description | Type | Value |
|---|---|---|---|
name |
Name of the connector | string | This must be unique across the Connect cluster |
topics |
The topics to sink.
The connector will check this matchs the KCQL statement
|
string | |
tasks.max |
The number of tasks to scale output | int | 1 |
connector.class |
Name of the connector class | string | com.datamountaineer.streamreactor.connect.mqtt.sink.MqttSinkConnector |
Connector Configurations¶
| Config | Description | Type |
|---|---|---|
connect.mqtt.kcql |
Kafka connect query language expression.
Allows for expressive MQTT topic to Kafka
topic routing. Currently, there is no support
for filtering the fields from the incoming payload
|
string |
connect.mqtt.hosts |
Specifies the mqtt connection endpoints | string |
Optional Configurations¶
| Config | Description | Type | Default |
|---|---|---|---|
connect.mqtt.service.quality |
The Quality of Service (QoS)
level is an agreement between sender
and receiver of a message regarding
the guarantees of delivering a message.
There are 3 QoS levels in MQTT:
At most once (0); At least once (1);
Exactly once (2)
|
int | 1 |
connect.mqtt.username |
Contains the MQTT connection user name | string | |
connect.mqtt.password |
Contains the MQTT connection password | string | |
connect.mqtt.client.id |
Provides the client connection
identifier.
If it is not provided the mqtt
will generate one
|
string | |
connect.mqtt.connection.timeout |
Sets the timeout to wait in milliseconds
for the broker connection to be established
|
int | 300 |
connect.mqtt.connection.clean |
The clean session flag indicates the broker,
whether the client wants to establish a persistent session or not.
A persistent session (the flag is false) means, that the broker
will store all subscriptions for the client and also all missed
messages when subscribing with Quality of Service (QoS) 1 or 2.
If clean session is set to true, the broker won’t store anything
for the client and will also purge all information from a previous
persistent session
|
boolean | true |
connect.mqtt.connection.keep.alive |
The keep-alive functionality
assures that the connection is still open and
both broker and client are connected to one another.
Therefore the client specifies a time interval in
seconds and communicates it to the broker during
the establishment of the connection.
The interval is the longest possible period of time in milliseconds,
which broker and client can endure without sending a message
|
int | 5000 |
connect.mqtt.connection.ssl.ca.cert |
Provides the path to the CA
certificate file to use with the MQTT connection
|
string | |
connect.mqtt.connection.ssl.cert |
Provides the path to the certificate
file to use with the MQTT connection
|
string | |
connect.mqtt.connection.ssl.key |
Certificate private key file path | string | |
connect.mqtt.error.policy |
Specifies the action to be
taken if an error occurs while inserting the data.
There are three available options, NOOP, the error
is swallowed, THROW, the error is allowed
to propagate and retry.
For RETRY the Kafka message is redelivered up
to a maximum number of times specified by the
connect.mqtt.max.retries option |
string | THROW |
connect.mqtt.max.retries |
The maximum number of times a message
is retried. Only valid when the
connect.mqtt.error.policy is set to RETRY |
string | 10 |
connect.mqtt.retry.interval |
The interval, in milliseconds between retries,
if the sink is using
connect.mqtt.error.policy set to RETRY |
string | 60000 |
connect.progress.enabled |
Enables the output for how many
records have been processed
|
boolean | false |
Example¶
name=mqtt-sink
connector.class=com.datamountaineer.streamreactor.connect.mqtt.sink.MqttSinkConnector
tasks.max=1
connect.mqtt.clean=true
connect.mqtt.timeout=1000
connect.mqtt.keep.alive=1000
connect.mqtt.client.id=dm_source_id,
connect.mqtt.hosts=tcp://127.0.0.1:11883
connect.mqtt.service.quality=1
connect.mqtt.kcql=INSERT INTO mqtt_topic SELECT * FROM kafka_topic
connect.progress.enabled=true
Kubernetes¶
Helm Charts are provided at our repo, add the repo to your Helm instance and install. We recommend using the Landscaper to manage Helm Values since typically each Connector instance has its own deployment.
Add the Helm charts to your Helm instance:
helm repo add landoop https://landoop.github.io/kafka-helm-charts/
TroubleShooting¶
Please review the FAQs and join our slack channel