ReThink Source¶
Download connector ReThinkDB Connector for Kafka 2.1.0
A Kafka Connector and Source to write events from ReThinkDB to Kafka. The connector subscribes to change feeds on tables and streams the records to Kafka.
Prerequisites¶
- Apache Kafka 0.11.x or above
- Kafka Connect 0.11.x or above
- RethinkDB 2.3.3 or above
- Java 1.8
Features¶
- The KCQL routing querying - Table to topic routing
- Initialization (Read feed from start) via KCQL
- ReThinkDB type (add, delete, update). The feed a change data capture of mutations
- ReThinkDB initial states
KCQL Support¶
INSERT INTO kafka_topic SELECT * FROM rethink_table [INITIALIZE] [BATCH ...]
Tip
You can specify multiple KCQL statements separated by ; to have a the connector sink multiple topics.
The ReThinkDB source supports KCQL, Kafka Connect Query Language. The following support KCQL is available:
- Selection of RethinkDB tables to listen for change on
- Selection of the target topic in Kafka
- Whether to initialize the feed from the start
- Setting the batch size of the feed.
Example:
-- Insert into Kafka the change feed from tableA
INSERT INTO topicA SELECT * FROM tableA
-- Insert into topicA the change feed from tableA, read from start
INSERT INTO tableA SELECT * FROM topicA INITIALIZE
-- Insert into topicA the change feed from tableA, read from start, read from start and batch 100 rows to send to kafka
INSERT INTO tableA SELECT * FROM topicA INITIALIZE BATCH 100
Lenses QuickStart¶
The easiest way to try out this is using Lenses Box the pre-configured docker, that comes with this connector pre-installed. You would need to Connectors –> New Connector –> Source –> Rethink and paste your configuration
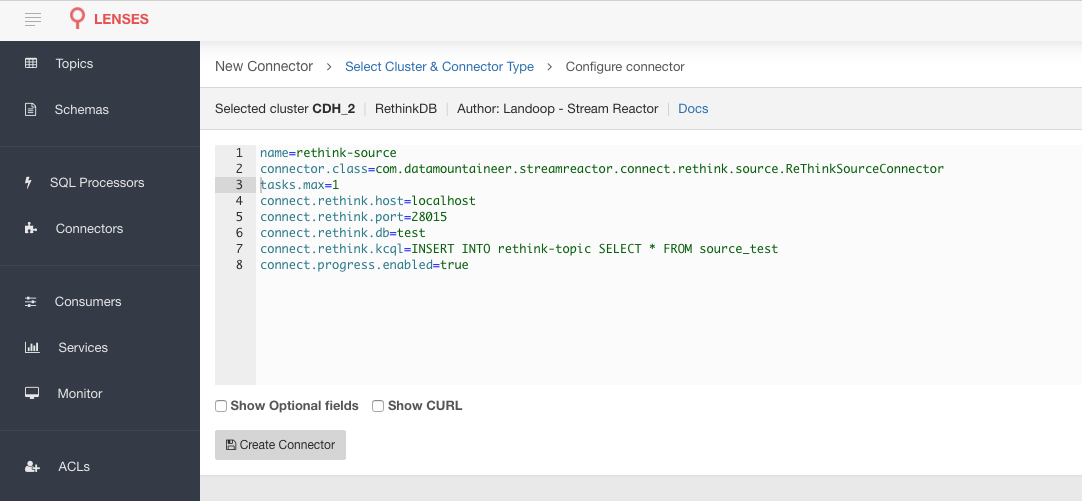
Rethink Setup¶
Download and install RethinkDb. Follow the instruction here dependent on your operating system.
Installing the Connector¶
Connect, in production should be run in distributed mode
- Install and configure a Kafka Connect cluster
- Create a folder on each server called
plugins/lib - Copy into the above folder the required connector jars from the stream reactor download
- Edit
connect-avro-distributed.propertiesin theetc/schema-registryfolder and uncomment theplugin.pathoption. Set it to the root directory i.e. plugins you deployed the stream reactor connector jars in step 2. - Start Connect,
bin/connect-distributed etc/schema-registry/connect-avro-distributed.properties
Connect Workers are long running processes so set an init.d or systemctl service accordingly.
Sink Connector QuickStart¶
Start Kafka Connect in distributed mode (see install).
In this mode a Rest Endpoint on port 8083 is exposed to accept connector configurations.
We developed Command Line Interface to make interacting with the Connect Rest API easier. The CLI can be found in the Stream Reactor download under
the bin folder. Alternatively the Jar can be pulled from our GitHub
releases page.
Starting the Connector (Distributed)¶
Download, and install Stream Reactor. Follow the instructions here if you haven’t already done so. All paths in the quickstart are based on the location you installed the Stream Reactor.
Once the Connect has started we can now use the kafka-connect-tools cli to post in our distributed properties file for ReThinkDB. For the CLI to work including when using the dockers you will have to set the following environment variable to point the Kafka Connect Rest API.
export KAFKA_CONNECT_REST="http://myserver:myport"
➜ bin/connect-cli create rethink-source < conf/rethink-source.properties
name=rethink-source
connector.class=com.datamountaineer.streamreactor.connect.rethink.source.ReThinkSourceConnector
tasks.max=1
connect.rethink.host=localhost
connect.rethink.port=28015
connect.rethink.db=test
connect.rethink.kcql=INSERT INTO rethink-topic SELECT * FROM source-test
We can use the CLI to check if the connector is up but you should be able to see this in logs as well.
#check for running connectors with the CLI
➜ bin/connect-cli ps
rethink-source
INFO
__ __
/ / ____ _____ ____/ /___ ____ ____
/ / / __ `/ __ \/ __ / __ \/ __ \/ __ \
/ /___/ /_/ / / / / /_/ / /_/ / /_/ / /_/ /
/_____/\__,_/_/ /_/\__,_/\____/\____/ .___/
/_/
____ ________ _ __ ____ ____ _____
/ __ \___/_ __/ /_ (_)___ / /__/ __ \/ __ ) ___/____ __ _______________
/ /_/ / _ \/ / / __ \/ / __ \/ //_/ / / / __ \__ \/ __ \/ / / / ___/ ___/ _ \
/ _, _/ __/ / / / / / / / / / ,< / /_/ / /_/ /__/ / /_/ / /_/ / / / /__/ __/
/_/ |_|\___/_/ /_/ /_/_/_/ /_/_/|_/_____/_____/____/\____/\__,_/_/ \___/\___/
By Andrew Stevenson (com.datamountaineer.streamreactor.connect.rethink.source.ReThinkSourceTask:48)
Test Records¶
Go to the ReThink Admin console http://localhost:8080/#tables and add a database called test and table called source-test. Then on the Data Explorer tab insert the following and hit run to insert the record into the table.
r.table('source_test').insert([
{ name: "datamountaineers-rule", tv_show: "Battlestar Galactica",
posts: [
{title: "Decommissioning speech3", content: "The Cylon War is long over..."},
{title: "We are at war", content: "Moments ago, this ship received word..."},
{title: "The new Earth", content: "The discoveries of the past few days..."}
]
}
])
Check for records in Kafka¶
Check for records in Kafka with the console consumer.
➜ bin/kafka-avro-console-consumer \
--zookeeper localhost:2181 \
--topic rethink-topic \
--from-beginning
{"state":{"string":"initializing"},"old_val":null,"new_val":null,"type":{"string":"state"}}
{"state":{"string":"ready"},"old_val":null,"new_val":null,"type":{"string":"state"}}
{"state":null,"old_val":null,"new_val":{"string":"{tv_show=Battlestar Galactica, name=datamountaineers-rule, id=ec9d337e-ee07-4128-a830-22e4f055ce64, posts=[{title=Decommissioning speech3, content=The Cylon War is long over...}, {title=We are at war, content=Moments ago, this ship received word...}, {title=The new Earth, content=The discoveries of the past few days...}]}"},"type":{"string":"add"}}
Record Schema¶
The connectors subscribes to change feeds, theses feed provide a new and old value. The connector constructs the following schema for this feed:
| Name | Description | Type |
|---|---|---|
| state | The changefeed stream will include
special status documents consisting of the
field state and a string indicating a change
in the feed’s state.
{:state => ‘initializing’} indicates the following
documents represent initial values on the feed rather than changes.
This will be the first document of a feed that returns initial values.
{:state => ‘ready’} indicates the following documents represent changes.
This will be the first document of a feed that does not return initial values;
otherwise, it will indicate the initial values have all been sent
|
optional string |
| oldVal | The old value before the mutation | optional string |
| newVal | The new value record after the mutation | optional string |
| type | Mutation type
add: a new value added to the result set.
remove: an old value removed from the result set.
change: an existing value changed in the result set.
initial: an initial value notification.
uninitial: an uninitial value notification.
state: a status document from include_states
|
optional string |
Configurations¶
The Kafka Connect framework requires the following in addition to any connectors specific configurations:
| Config | Description | Type | Value |
|---|---|---|---|
name |
Name of the connector | string | |
tasks.max |
The number of tasks to scale output | int | 1 |
connector.class |
Name of the connector class | string | com.datamountaineer.streamreactor.connect.rethink.source.ReThinkSourceConnector |
Connector Configurations¶
| Config | Description | Type |
|---|---|---|
connect.rethink.kcql |
Kafka connect query language expression. Allows for expressive topic to table
routing, field selection and renaming. Fields to be used as the row key
can be set by specifying the
PK |
string |
connect.rethink.host |
Specifies the rethink server host | string |
Optional Configurations¶
| Config | Description | Type |
|---|---|---|
connect.rethink.port |
Specifies the rethink server port number. Default: 28015 | int |
connect.rethink.db |
Specifies the rethink database to connect to. Default: connect_rethink_sink | string |
connect.rethink.batch.size |
The number of records to drain from the internal queue on each poll. Default : 1000 | int |
connect.rethink.linger.ms |
The number of milliseconds to wait before flushing the received messages to Kafka.
The records will be flushed if the batch size is reached before the linger
period has expired. Default : 5000
|
int |
connect.rethink.cert.file |
Certificate file to connect to a TLS enabled ReThink cluster. Cannot be
used in conjunction with username/password.
connect.rethink.auth.key must also be set |
string |
connect.rethink.auth.key |
Authentication key to connect to a TLS enabled ReThink cluster. Cannot be
used in conjunction with username/password.
connect.rethink.cert.file must be set |
string |
connect.rethink.username |
Username to connect to ReThink with | string |
connect.rethink.password |
Password to connect to ReThink with | string |
connect.rethink.ssl.enabled |
Enables SSL communication against an SSL enabled Rethink cluster | boolean |
connect.rethink.trust.store.password |
Password for truststore | string |
connect.rethink.key.store.path |
Path to truststore | string |
connect.rethink.key.store.password |
Password for key store | string |
connect.rethink.ssl.client.cert.auth |
Path to keystore | string |
connect.progress.enabled |
Enables the output for how many records have been processed. Default : false | boolean |
Example¶
name=rethink-source
connector.class=com.datamountaineer.streamreactor.connect.rethink.source.ReThinkSourceConnector
tasks.max=1
connect.rethink.host=localhost
connect.rethink.port=28015
connect.rethink.kcql=INSERT INTO rethink-topic SELECT * FROM source-test
Schema Evolution¶
The schema is fixed. The following schema is used:
| Name | Type | Optional |
| state | string | yes |
| new_val | string | yes |
| old_val | string | yes |
| type | string | yes |
Kubernetes¶
Helm Charts are provided at our repo, add the repo to your Helm instance and install. We recommend using the Landscaper to manage Helm Values since typically each Connector instance has its own deployment.
Add the Helm charts to your Helm instance:
helm repo add landoop https://landoop.github.io/kafka-helm-charts/
TroubleShooting¶
Please review the FAQs and join our slack channel